Hi David,
Could you pls clarify my doubt stated below -
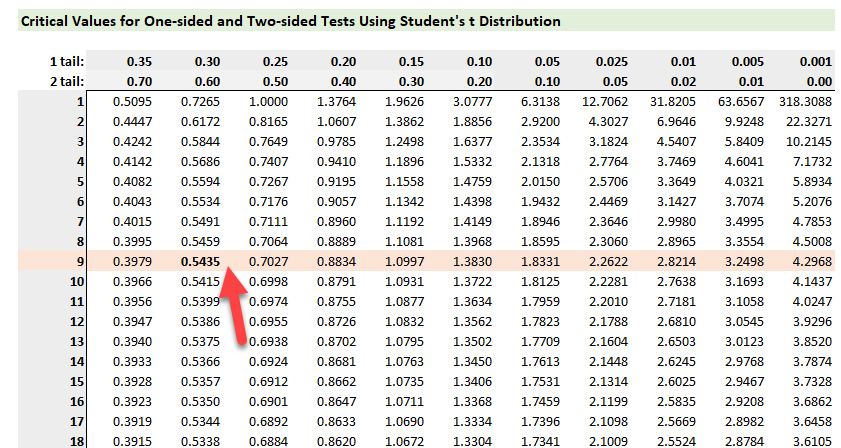
When we did the hypothesis test in VAR chapter and calculated the t-statistic value, we always use to compare it with critical/look up value based on confidence level to make a call whether to reject or accept the hypothesis. So we were getting away in calculating the p-value here.
But when we reached linear regression chapter - we don't have a confidence level. So when we performed the hypothesis test and calculated our t-statistic number and let's presume it comes (as you said on the video) around 2 and 3 which is our sweet spot, we have to make a call to reject/accept from the p-value. My question is - how should we calculate the p value from t-statistic number and how to interpret the p-value once we have it?
Many Thanks,
atandon
Could you pls clarify my doubt stated below -
When we did the hypothesis test in VAR chapter and calculated the t-statistic value, we always use to compare it with critical/look up value based on confidence level to make a call whether to reject or accept the hypothesis. So we were getting away in calculating the p-value here.
But when we reached linear regression chapter - we don't have a confidence level. So when we performed the hypothesis test and calculated our t-statistic number and let's presume it comes (as you said on the video) around 2 and 3 which is our sweet spot, we have to make a call to reject/accept from the p-value. My question is - how should we calculate the p value from t-statistic number and how to interpret the p-value once we have it?
Many Thanks,
atandon