Hello,
I would like to ask what is the correct form of Z and t-statistics. If I am not mistaken it is
[mu-X(h)]/SE,
where mu = population mean, observed value or beta in case of regression and X(h) is the tested value or null hypothesis.
Are there any cases when the numerator should be X(h) - mu instead? I found several in the question sets (P1.T2.317.3, P1.T2.319.1, P1.T2.403.2, P1.T2.405.1, P1.T2.405.2)
I guess I am missing some piece to understand...Thank you a lot!
I would like to ask what is the correct form of Z and t-statistics. If I am not mistaken it is
[mu-X(h)]/SE,
where mu = population mean, observed value or beta in case of regression and X(h) is the tested value or null hypothesis.
Are there any cases when the numerator should be X(h) - mu instead? I found several in the question sets (P1.T2.317.3, P1.T2.319.1, P1.T2.403.2, P1.T2.405.1, P1.T2.405.2)
I guess I am missing some piece to understand...Thank you a lot!
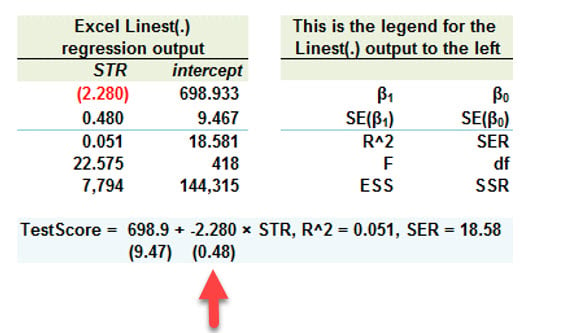
 ...
...