Hi BT forum,
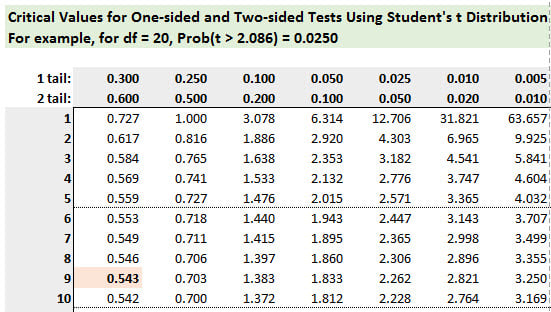
Need your help, I'm thoroughly confused by this question and its answer - since the calculated t-value equals the critical t at 5%, aren't we saying we are accepting the null hypothesis that the population average refund mu=$882 (assuming that was the null since alternative is mu>$882)? And given that first step, isn't the question asking to calculate the 99% confidence interval for the "true" population average tax refund?
Looking at the answer though, it seems we are saying the population average is $1,000 like the sample. Can someone please explain why we would not be using mu = $882 +/- 2.898 * Std Error? (Seems the sample standard deviation formula also divides by sqrt(d.f.) when it should be sqrt(n)?)
thanks
Need your help, I'm thoroughly confused by this question and its answer - since the calculated t-value equals the critical t at 5%, aren't we saying we are accepting the null hypothesis that the population average refund mu=$882 (assuming that was the null since alternative is mu>$882)? And given that first step, isn't the question asking to calculate the 99% confidence interval for the "true" population average tax refund?
Looking at the answer though, it seems we are saying the population average is $1,000 like the sample. Can someone please explain why we would not be using mu = $882 +/- 2.898 * Std Error? (Seems the sample standard deviation formula also divides by sqrt(d.f.) when it should be sqrt(n)?)
thanks
 . Yikes, I understand the difference now, and at the same time REALLY worried I traveled down that path. Thanks for clearing this up for me.
. Yikes, I understand the difference now, and at the same time REALLY worried I traveled down that path. Thanks for clearing this up for me.