Learning objectives: Describe the issues unique to big datasets. Explain and assess different tools and techniques for manipulating and analyzing big data. Examine the areas for collaboration between econometrics and machine learning.
Questions:
802.1. Below is Hal Varian's simple classification tree that predicts Titanic survivors (Figure 1 in the reading).
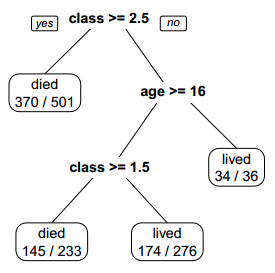
According to the tree, each of the following statements is true EXCEPT which is inaccurate?
a. This testing set contain 1,046 observations and two features
b. The tree predicts that all passengers who are younger than 16 will survive
c. The rules in this tree misclassify about 30.9% of the "in sample" (testing set) observations
d. The tree predicts that all First Class passengers will survive, but only some Second Class passengers will survive
802.2. With respect to tools and techniques for manipulating and analyzing big data, each of the following statements is true EXCEPT which is false?
a. Classifier performance is often improved by adding randomness and examples of this include boosting, bagging and bootstrapping
b. When using a large data set (e.g., big data), the data should be parsed at least into separate training and testing sets; or even training, validation, and testing sets
c. Random forests have the advantage of intuitive usability by offering simple summaries of data relationships, but their disadvantage is inferior out-of-sample performance especially with nonlinear data
d. Pruning a tree is an example of regularization because it imposes a cost for tree complexity (e.g., number of terminal nodes) with the goal of simplifying the model and generating better out-of-sample predictions
802.3. As an illustrative example of the "most important area for collaboration" between econometrics and machine learning, Hal Varian considers a (case study) relationship between advertising campaigns and website visits. With respect to this case study, which of the following BEST summarizes the key insight that illustrates his recommended collaboration between econometrics and machine learning?
a. The study substitutes a predictive model for a conventional control group in order to demonstrate causality
b. The study employs machine learning in order to generate a model with a higher multiple coefficient of determination
c. The study borrows from econometrics in a way that better generates exploratory data analysis (EDA) and renders the complex relationships easier to understand
d. A BSTS model forecasts directly the beta coefficient of advertising spend as an explanatory variable, then econometric methods are employed to overlay time-series covariates
Answers here:
Questions:
802.1. Below is Hal Varian's simple classification tree that predicts Titanic survivors (Figure 1 in the reading).
According to the tree, each of the following statements is true EXCEPT which is inaccurate?
a. This testing set contain 1,046 observations and two features
b. The tree predicts that all passengers who are younger than 16 will survive
c. The rules in this tree misclassify about 30.9% of the "in sample" (testing set) observations
d. The tree predicts that all First Class passengers will survive, but only some Second Class passengers will survive
802.2. With respect to tools and techniques for manipulating and analyzing big data, each of the following statements is true EXCEPT which is false?
a. Classifier performance is often improved by adding randomness and examples of this include boosting, bagging and bootstrapping
b. When using a large data set (e.g., big data), the data should be parsed at least into separate training and testing sets; or even training, validation, and testing sets
c. Random forests have the advantage of intuitive usability by offering simple summaries of data relationships, but their disadvantage is inferior out-of-sample performance especially with nonlinear data
d. Pruning a tree is an example of regularization because it imposes a cost for tree complexity (e.g., number of terminal nodes) with the goal of simplifying the model and generating better out-of-sample predictions
802.3. As an illustrative example of the "most important area for collaboration" between econometrics and machine learning, Hal Varian considers a (case study) relationship between advertising campaigns and website visits. With respect to this case study, which of the following BEST summarizes the key insight that illustrates his recommended collaboration between econometrics and machine learning?
a. The study substitutes a predictive model for a conventional control group in order to demonstrate causality
b. The study employs machine learning in order to generate a model with a higher multiple coefficient of determination
c. The study borrows from econometrics in a way that better generates exploratory data analysis (EDA) and renders the complex relationships easier to understand
d. A BSTS model forecasts directly the beta coefficient of advertising spend as an explanatory variable, then econometric methods are employed to overlay time-series covariates
Answers here:
Last edited by a moderator: